Performance90 is a service for PageSpeed monitoring. It notifies the page owner once the PageSpeed drops below 90 via email.
The tech stack is Remix with Kysely on SQLite with Litestream and fly.io.Note: This blog post is not a step-by-step tutorial. It’s a high-level overview of the architecture showing trade-offs of design decisions. Ideally, the reader is familiar with Remix (or similar), TypeScript, and SQL databases.
Product
Performance90 is a free service that can be used without registration. A good way to explain a product is to look at the problem it solves.
Problem
Google launched Core Web Vitals (CWV) a couple of years back. CWV affects the PageSpeed/Lighthouse score.
 In order to remove friction, magic links replace password-based logins. This has some security implications, but we won’t discuss those in this post.
In order to remove friction, magic links replace password-based logins. This has some security implications, but we won’t discuss those in this post.
The default threshold is 90, which Google considers a good PageSpeed.
Tech stack
The main feature of the product is laid out. Let’s look at the tech stack.
Remix (vs. Django)
I am equally proficient in both frameworks and ecosystems. Django would’ve saved me some time with infrastructure, but typed JSX and typed SQL queries pay long-term dividends.
The low-key side quest was to build something, that doesn’t make me miss Django that much when using TypeScript.
I could have gone for Next.js or SvelteKit. I consider those frameworks closely related in the context of this post. So most of the statements regarding Remix are true for similar frameworks.
Kysely (vs. Prisma)
Prisma is the default tool for persistence in many newer “meta frameworks” like Remix, Next.js, or RedwoodJS. The product itself is great, the developer experience is nice and it makes me productive long-term.
Personally, I am waiting for Prisma to prove that they’ve built a sustainable business before I put their abstraction layer on top of SQL.
Kysely is simpler in a few ways. It was developed by the guy who built Objection.js. The bus factor isn’t great compared to Prisma. However, if it comes to it, I have to dig into a TypeScript query builder similar to Knex.js. I see a higher chance of fixing things myself should koskimas abandon the project.
I feel as productive with Kysely as with Prisma.
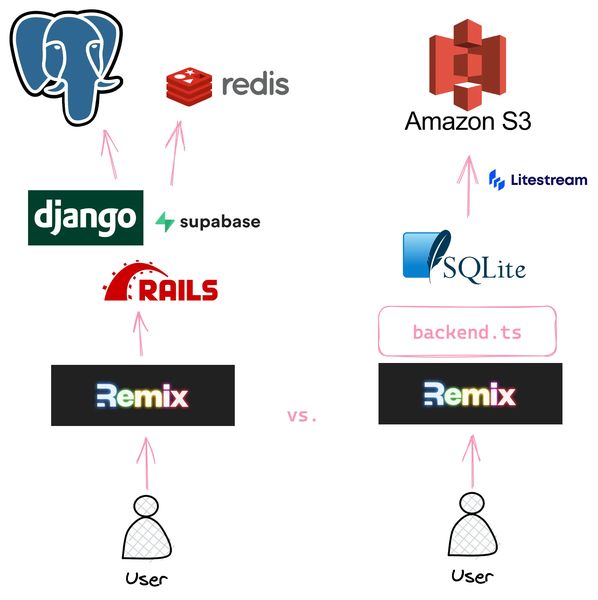
SQLite & Litestream (vs. Postgres)
I consider Postgres to be boring in the best possible way. It’s the default choice for anything serious that needs to scale.
To start out, I prefer an even simpler setup where Litestream streams an SQLite database into an S3 bucket.
I don’t have to use a managed database service and I get backups and point-in-time restores.
Architecture
Remix does like 30% of what Django does.
 You start a project with Remix. Initially, it has everything needed. Maybe you need to pull in one or two libraries to get the job done.
You start a project with Remix. Initially, it has everything needed. Maybe you need to pull in one or two libraries to get the job done.
Soon enough, the missing 70% starts to become painfully apparent. When starting a greenfield project with Remix, there are 3 options:
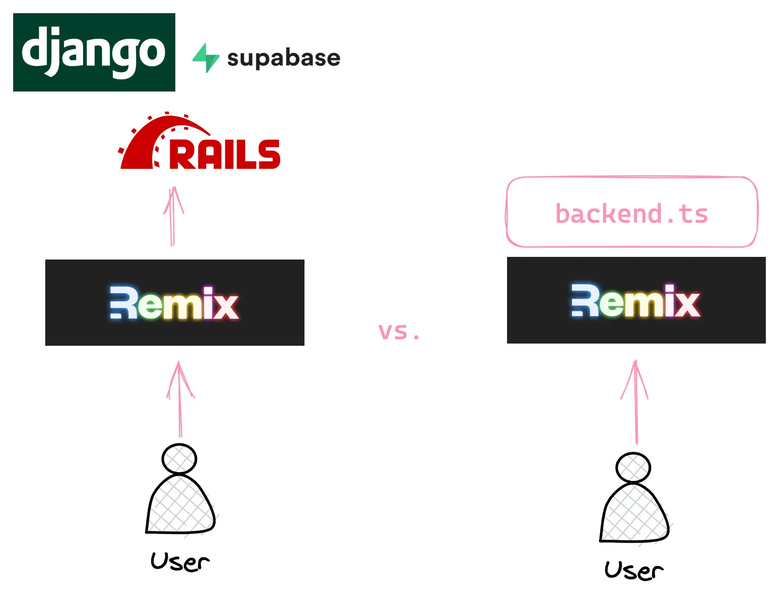 Use a traditional web framework as a backend (like Django)
Use a traditional web framework as a backend (like Django)
- Use a headless backend (like Supabase or Directus)
- Write your own ad-hoc backend in TypeScript
I mentioned the low-key side quest of building something that replaces Django when using Remix. Performance90 goes with approach #3 and comes with its own backend. With time, the backend could cover those missing 70%.
Note: I suspect quite some projects go with #3 but don’t make that decision explicit. Without explicit design decisions, Remix projects contain routes, loaders, action handlers and loosely coupled functions that talk to the database.
Litestream
With a traditional approach using something like Django, you’d typically pick Postgres and Redis. Depending on the exact stack and scale, you have to operate 5+ services/processes right away.
Compare that to streaming SQLite changes with Litestream into an S3 bucket. There is a single service to maintain.
 Service orientation
Service orientation
The architecture of the backend is service-oriented (SOA). Every piece of functionality is provided by a service.
For instance, the email service sends emails:
// lib/email/types.ts
export interface EmailService {
send(email: Email): Promise<void>;
}And the migration service applies database migrations and creates empty migration files:
// lib/migration/types.ts
interface MigrationService {
migrate(): Promise<void>;
createEmptyFile(): Promise<void>;
}Services can use other services and their dependencies. Dependencies get injected into the services.
Performance90 uses the iti library for dependency injection.
This is the container containing all services, it gives you a good overview of the current feature set:
// lib/container.ts
const container = createContainer().add((ctx) => ({
config: () => new ConfigService(/* deps omitted */),
database: () => new DatabaseService(/* deps omitted */),
emailService: () => new EmailService(/* deps omitted */),
seedService: () => new SeedService(/* deps omitted */),
migrationService: () => new MigrationService(/* deps omitted */),
userService: () => new UserService(/* deps omitted */),
sessionService: () => new SessionService(/* deps omitted */),
magicLinkService: () => new MagicLinkService(/* deps omitted */),
cliService: () => new CLIService(/* deps omitted */),
}));For brevity, all dependencies have been removed. Such a container is also called a service container.
Remix handlers retrieve service instances like so:
// app/routes/index.tsx
export async function loader({ request }: LoaderArgs) {
const user = await container.items.sessionService.requireUser(request);
// do stuff
return json({
/* stuff */
});
}The real service container setup is more verbose because it has all service dependencies.
This is an excerpt showing the SeedService and MigrationService and their dependencies:
// lib/container.ts
// ...
.add((ctx) => ({
seedService: () =>
new SeedService(
ctx.database,
ctx.config.seedsFolder(),
ctx.config.env()
),
}))
.add((ctx) => ({
migrationService: () =>
new SQLMigrationService(
ctx.database,
ctx.config.migrationsFolder()
),
}))
// ...The SeedService depends on
- the DatabaseService
- the path of the seeds
- and the current NODE_ENV value.
Dependency injection sounds scary, but it really isn’t (unless you have a Spring background, then the fear will stay with you forever).
Providing dependencies to the constructor as arguments is a form of dependency injection.
Note: If you are breathing SOA and are wondering where the repositories are, they are gone. I acknowledge the value of repos but for this project, I went with a lightweight approach that embraces SQL instead of hiding it.
A good way to grow this code base would be to introduce repos.
Schema-aware type-safe queries
This is where Kysely comes in. It’s aware of the database schema and it allows you to write type-safe SQL queries in TypeScript.
Kysely needs TypeScript types that mirror the database schema…
// lib/schema.ts
import type { Tables as LibTables } from "~/lib/core/schema";
import type { Generated, Kysely, Selectable } from "kysely";
export type MeasurementsTable = {
internalId: Generated<number>;
id: string;
pageId: string;
performance: number | null;
startedAt: number | null;
finishedAt: number | null;
};
export type Measurement = Selectable<MeasurementsTable>;
export type PagesTable = {
internalId: Generated<number>;
id: string;
userId: string;
url: string;
threshold: number;
createdAt: number;
};
export type Page = Selectable<PagesTable>;
export type Tables = {
measurements: MeasurementsTable;
pages: PagesTable;
} & LibTables;
export type Db = Kysely<Tables>;..in order to provide us schema-aware type-safe queries:
// services/measurement/service.ts
// ...
async findPagesWithMeasurementByUser(user: User) {
return this.database
.selectFrom("pages")
.innerJoin("users", "users.id", "pages.userId")
.select([
"pages.id as id",
"url",
"threshold",
(qb) =>
qb
.selectFrom("measurements")
.whereRef("measurements.pageId", "=", "pages.id")
.select("measurements.performance")
.orderBy("internalId", "desc")
.limit(1)
.as("lastPerformance"),
(qb) =>
qb
.selectFrom("measurements")
.whereRef("measurements.pageId", "=", "pages.id")
.select("measurements.finishedAt")
.orderBy("internalId", "desc")
.limit(1)
.as("lastMeasurementAt"),
])
.where("users.id", "=", user.id)
.execute();
}
// ...It’s not possible to select a field or query a table that doesn’t exist. Kysely uses an advanced TypeScript feature called Template Literal Types.
The field alias lastPerformance and lastMeasurementAt are correctly inferred, too.
The best part: it’s just SQL. Which means you get to use all your SQL knowledge. If you don’t have any, it’s a good way to learn some SQL!
The only drawback is the synchronization of the TypeScript schema with the actual database tables. There are a few code generators that introspect the database schema and generate the TypeScript schema.
None of them worked reliably for me, so I maintain them by hand for now.
Kysely has a powerful plugin system, which allows me to automatically convert camelCase to snake_case. It allows me to completely forget about snake_case.
CRUD services
Let’s define CRUD services like the following:
// lib/core/service.ts
export interface Service<E extends Table> {
find(id: string): Promise<Selectable<E> | undefined>;
findOrThrow(id: string): Promise<Selectable<E>>;
findAll(limit?: number, offset?: number): Promise<Selectable<E>[]>;
insert(entity: Insertable<E>): Promise<void>;
update(entity: Insertable<E>): Promise<void>;
delete(entity: Selectable<E>): Promise<void>;
refresh(entity: E): Promise<void>;
}With a simple base CRUD service, it’s easy to implement custom CRUD services that help us to get up and running quickly.
Following is the implementation of a UserService that implements 7 methods using the users database table for free.
// lib/user/service.ts
export default class UserService extends CrudService<UsersTable> {
constructor(readonly database: Db) {
super(database, "users");
}
async create(email: string) {
const now = Date.now();
const user: Insertable<UsersTable> = {
id: nanoid(),
email,
joinedAt: now,
lastLoginAt: null,
};
await this.insert(user);
return this.findOrThrow(user.id);
}
}Services grow and soon they won’t be CRUD only.
It’s trivial to extend them:
// lib/user/service.ts
// ...
async deleteByEmail(email: string) {
return this.database
.deleteFrom("users")
.where("users.email", "=", email)
.execute();
}
// ...Configuration
Every feature is provided by a service, including configuration management. In fact, the ConfigService is the very first service that is instantiated.
The ConfigService reads env vars from .env files and from the process environment process.env. It provides type-safe methods to read those values.
The default ConfigService has the following interface:
// lib/config/types.ts
export interface ConfigService {
domain(): string;
senderAddress(): string;
databaseUrl(): string;
migrationsFolder(): string;
magicLinkSecret(): string;
baseUrl(): string;
env(): Env;
runInEnv<A>(e: {
production: () => A;
test?: () => A;
development?: () => A;
}): A;
}Custom config service
In order to use custom configurations or to override defaults, simply extend the default ConfigService and add or override methods to create an app-specific AppConfigService.
EnvConfigService is the default implementation that reads configuration from environment vars.
// services/config/service.ts
export default class AppConfigService extends EnvConfigService {
domain(): string {
return "performance90.com";
}
}Overwrite the default EnvConfigService with the AppConfigService instance. This mechanism is the reason that CTRL+F “mocking” will give you just one result on this blog post. Simply create an ad-hoc service and overwrite it for testing.
const testContainer = libContainer().upsert(() => ({
config: () => new AppConfigService(),
}));The code blows gives a TypeScript error, because a config service has been inserted already. In order to overwrite services with custom services you have to use upsert.
const testContainer = libContainer().insert(() => ({
config: () => new AppConfigService(),
}));Working with multiple environments
Sometimes you want different service instances depending on the NODE_ENV value.
Let’s take the EmailService for instance:
- in production, you want the PostmarkEmailService instance
- in development, the ConsoleEmailService and
- in testing the InmemoryEmailService.
Using the runInEnv helper method of the ConfigService, this can be expressed declaratively:
// lib/sontainer.ts
const container createContainer()
.add((ctx) => ({
// ...
emailService: () =>
ctx.config.runInEnv({
production: () =>
new PostmarkEmailService(
ctx.config.postmarkEmailToken(),
ctx.config.senderAddress(),
ctx.config.domain()
),
test: () =>
new InmemoryEmailService(
ctx.config.senderAddress("sender@example.com")
),
development: () =>
new ConsoleEmailService(
ctx.config.senderAddress("sender@example.com")
),
}),
}))The default service container uses the correct service instances depending on the NODE_ENV, which are set when running npm run test or npm run dev.
Migrations
Performance90 uses Kysely for migrations. It maintains a single migration history where every migration has up and down handlers.
// migrations/2021_09_18_06_54_59_initialize.ts
import type { Kysely } from "kysely";
export async function up(db: Kysely<any>): Promise<void> {
await db.schema
.createTable("users")
.ifNotExists()
.addColumn("internalId", "serial", (col) => col.primaryKey())
.addColumn("id", "text", (col) => col.unique().notNull())
.addColumn("email", "text", (col) => col.unique().notNull())
.addColumn("joinedAt", "integer", (col) => col.notNull())
.addColumn("lastLoginAt", "integer")
.execute();
await db.schema
.createIndex("usersIdIndex")
.ifNotExists()
.on("users")
.column("id")
.execute();
await db.schema
.createIndex("usersEmailIndex")
.ifNotExists()
.on("users")
.column("email")
.execute();
}
export async function down(db: Kysely<any>): Promise<void> {}The type-safety is a bit weaker compared to the query API because of Kysely<any>. You’d have to provide Kysely with the database schema before the migration application in order to get full schema-aware type safety.
For this, you’d have to maintain a schema between each migration. The extra type-safety is not worth it, because migrations are write-only.
Note: I don’t bother implementing downward migrations. I never migrated down in 7 years of web development. Recovering production databases, on the other hand, happened a few times. I rather spend more time and energy on the backup & recovery story.
Testing
Performance90 uses vitest for testing.
// lib/user/service.test.ts
import { cleanAll } from "~/lib/test";
import createContainer from "~/lib/container";
// instantiate the service container
const container = createContainer();
// run migrations once before all tests
beforeAll(async () => {
await container.items.migrationService.migrate();
});
// clean database before every test
beforeEach(async () => {
await cleanAll(container.items.database);
});
test("create user", async () => {
const created = await container.items.userService.create("test@example.com");
const user = await container.items.userService.findOrThrow(created.id);
const found = await container.items.userService.findByEmail(
"test@example.com"
);
expect(user.id).toEqual(found.id);
});Every test suite creates its service container instance. If a service needs to be overwritten, it doesn’t affect other test suites.
The cleanAll helper fetches and cleans all tables in the database:
// lib/utils/test.ts
const tables = await database
.selectFrom("sqlite_schema")
.select("name")
.where("type", "=", "table")
.where("name", "not like", "sqlite_%")
.where("name", "not like", "kysely_%")
.execute();The DatabaseService creates an in-memory SQLite database if NODE_ENV is testing.
The developer experience with vitest is good. TypeScript just works and the assertion/expect API is reasonable and intuitive.
Command line
Sooner or later you want to run commands like npm run migrate or npm run seed. The backend of Performance90 has a CLIService that takes care of dispatching command line commands.
Let’s start with an entry point.
// cli.ts
import { container } from "./app/container.server";
container.get("cliService").run(process.argv).catch(console.error);It’s not possible to run this with node cli.ts because Node doesn’t understand TypeScript. Tackling this topic made me seriously consider using Deno instead of Node.
In the end, I decided to go with Node using tsx instead. (very unfortunate name if you ask me).
All the server code is compiled and bundled by Remix, which uses esbuild. Every service that is called in an action handler or in a loader is transpiled, bundled, and executed by Remix.
The problem is command line scripts that are executed outside the Remix context.
I went with tsx because it uses esbuild, too. It runs TypeScript without an additional build step, at least it hides the additional build step very well.
There was an issue with dynamic imports where migration files are dynamically imported. I found a workaround, but this CLI stuff is the wonkiest part of the backend.
The CLIService depends on all other services:
// lib/container.ts
// ...
.add((ctx) => ({
cliService: () =>
new CLIService(
ctx.config,
ctx.migrationService,
ctx.emailService,
ctx.userService,
ctx.seedService
),
}));
// ...// package.json
// ...
"migrate": "tsx cli.ts migrate",
"seed": "tsx cli.ts seed",
// ...Conclusion
These are the good aspects of this architecture and tech stack:
- Operationally very simple: There is something blissful about having a single Node process and a local SQLite instance in the same VM with Litestream backing up the database into an S3 bucket.
- Strong type-safety: With Kysely and TypeScript in React components, the type-safety is very strong. Types of Remix loaders and action handlers and service methods are inferred. The overhead in terms of manual type annotations for this type safety of is surprisingly low.
- Interactivity for free: Remix can be used from static pages to highly dynamic web apps. It’s straightforward to start out with static pages and to gradually add dynamic elements.
- UX-focused development: Compared to a web framework like Django, it’s idiomatic to start with routes and views in Remix. This leads to a much more customer-centered design, that starts with the UX of the customer and ends with the data model. Consider a Django or Rails project where you start with models and work your way to the UI.
There are some drawbacks to this approach as well:
- Not most productive for CRUD/form-y apps: If you want to build an app that is mostly forms that store and update data and you don’t care about the UX that much, a traditional framework like Django or Rails is the more productive choice.
- No redundancy: It’s not well supported to have a second Node instance running because of Litestream limitations. They are supposed to fix that in the next release, but I assume that the development slowed down a bit because of LiteFS.
Overall, it’s an efficient way to build a product like Performance90. And the long-term maintainability should hold up well against feature requests to make the UX fancy.
Next steps
I am considering extracting the backend as a library. This could be a backend for “Backend for Frontend” (BFF) frameworks like Remix, Next.js, SvelteKit, Astro, and so on.
It could be a lightweight version of NestJS (the backend, not the Vercel thing) that focuses on the pain points when working with BFF frameworks such as bundling (try using MikroORM with Remix).
You would use it if neither the headless backend (Supabase) nor the traditional framework (Django) does it for you.
It’s not much different from what we did with Sihl, which is a full-stack web framework for OCaml. At its core, there are only services.
Let me know what you think!