Together with my SO we built hoarddit.com, a website that helps everyone to discover art. It allows you to virtually trade art pieces.
This post describes how we spent our innovation points and why hoarddit is not an NFT.
The Core Mechanics
There is a market with art pieces, currently with about 50'000 unique pieces. Some are owned by other users, but most are still owned by the bank.
The price for a piece is usually somewhere between 50 and 500. When you visit hoarddit.com for the first time, you are given a balance of 1000. Every 5 seconds that you spend on hoarddit, your balance gets incremented.
You can buy art that you like with that play money. If you can not afford a piece, just like it so you can buy it once you have enough.
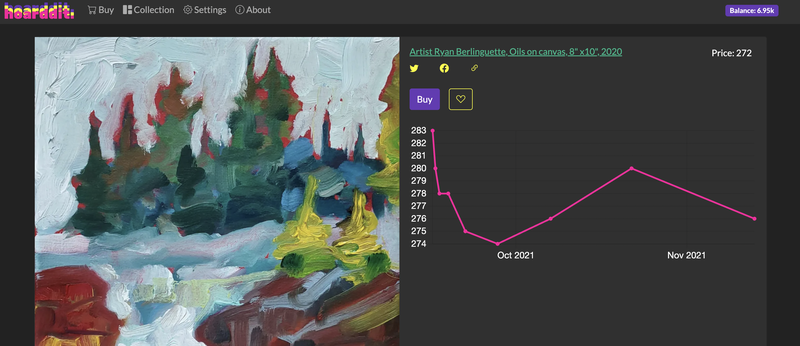
Your collection is the art that you bought and it is public. If you think you can sell a piece for a higher price, put it up for sale. Study the price chart to find trends.
The Feeling of Collecting
When we were younger, we were always collecting something. There were different phases where everyone in primary school was collecting the same things. One year it was Yu-Gi-Oh! cards, then it was Pokemon and during the FIFA world cup it was soccer player cards.
With hoarddit we wanted to recreate that feeling of building up a collection. The name is an amalgamation of hoarding and reddit because that is where the art is from.
However, collecting cards and collecting art on hoarddit are not the same thing. Usually, there are multiple people in the world that own the same Yu-Gi-Oh! cards, but an art piece on hoarddit can have only one owner.
When you buy a piece on hoarddit with your play money, you don’t actually own it. You only own the reference to the art on hoarddit.
Hoarddit guarantees that no one else owns a reference to the same piece. (At least that is the promise, in reality, we have to implement de-duplication.)
Owning a reference to art. Play money. Now this rings a bell. And for some, it might even raise a red flag.
Is It an NFT?
On hoarddit.com we state that the project is not an NFT. Is that really the case? Let’s examine the definition of an NFT on Wikipedia:
A non-fungible token (NFT) is a unique and non-interchangeable unit of data stored on a digital ledger (blockchain).
The art pieces on hoarddit are unique units of data stored in PostgreSQL. The definition says nothing about the ledger being distributed. If there was no mention about /blockchain, maybe one could argue that hoarddit is an NFT platform by this definition.
However, there is no blockchain involved, there are no tokens on distributed ledgers and most importantly, no one is getting rich overnight.
In fact, hoarddit costs couple of bucks a month to host and there are no plans to monetize it.
Boring Technology
We chose boring and tested technology that we were familiar with.
Hoarddit is a Django app using Postgres and good old server-side templates. For some dynamic components, HTMX was used. The design is powered by customized Bootstrap 5. For crawling and sending emails we are using Django Q.
Email sending uses the generous free tier of Mailjet. The whole thing is deployed on a Hetzner VPS using Dokku.
Sentry and Uptimerobot are used for monitoring and reporting.
This is the final picture, but it was a process to end up with this stack. A process that involved spending some innovation points.
Update 22.11.2021
We should at this point define innovation points.
In a project, we usually try to find a good balance between trying out new innovative (and potentially more productive) ways to do something and just getting things done. We tend to innovate/tinker/experiment too much and that’s why we give ourselves a limited amount of innovation points that we can spend within a project.
While developing hoarddit, we decided to try out new things on the UI side, so that is where we spent most of the innovation points.
Of course, that is more of a mental model and there are no actual points :)
Spending Innovation Points Deliberately
Early on during development, it became clear to us that hoarddit had some dynamic elements.
Users expect immediate feedback after clicking a like button. I dare you to try to refresh the page after the user leaves alike. Similar story to buying and selling art pieces.
 The most involved dynamic element however is infinite scrolling. Pagination by clicking next is out thanks to user metrics maximization. Even websites that have pagination in their name use infinite scrolling.
The most involved dynamic element however is infinite scrolling. Pagination by clicking next is out thanks to user metrics maximization. Even websites that have pagination in their name use infinite scrolling.
Which approach is the best in a situation like this? We spent some innovation points to find out.
React vs. AlpineJS vs. Vanilla JS vs. HTMX
React
Having worked with NextJS and React quite a bit, it was easy to eliminate React and the SPA approach.
We simply could not justify having a separate build process in a second language with a separate application lifecycle. The requirements define a limited amount of interactivity.
Of course, there is always that voice that tells you that you could power through all the complexity for a setup that can handle arbitrary dynamic and interactive web apps.
React is a great tool, but it might not be the best tool for the job.
AlpineJS¶
We like simple and small things without dependencies. AlpineJS’s philosophy seems to honor that. AlpineJS can be used with server-side templates, so we decided to give it a shot.
The installation was super easy. You include it in your HTML, no build process is needed, 10/10.
The first thing we implemented was the navigation bar. This was in an early version of hoarddit before we used the Bootstrap navigation component.
The documentation of AlpineJS is very good, we had a working navigation that opens and closes on click within seconds. So far so good.
Next, we wanted to implement the like feature. This involved an HTTP POST request. We did not do it inline but separated the behavior from the markup.
That went quite well, too. We were able to like and unlike art pieces within minutes.
Implementing the buy and sell features went similarly. However, we started to notice a pattern, a pattern that we did not like.
<svg
xmlns="http://www.w3.org/2000/svg"
class="h-6 w-6"
x-bind:fill="liked ? 'red' : 'none'"
fill="{% if detail.liked %}red{% else %}none{% endif%}"
viewBox="0 0 24 24"
x-bind:stroke="liked ? 'red' : 'currentColor'"
stroke="{% if detail.liked %}red{% else %}none{% endif%}"
>
...
</svg>
It is true that with AlpineJS you get to use good old server-side templates while you sprinkle some interactivity on top.
For more complex use cases, however, there will be a lot of duplication. Templating logic has to be written twice, once in the server-side templating language and once in AlpineJS.
Quickly we found ourselves googling terms such as AlpineJS server-side rendering hoping to find a solution on how to express the templates once and have Django and AlpineJS interpret them separately.
A term that was used frequently a few years back was isomorphic rendering. This describes the template rendering process on the server and on the client being somewhat similar.
If you use the term isomorphic rendering with this wonky definition and a Haskeller is nearby, you did not read it here!
AlpineJS was a joy to use for little stateless elements like the navigation that opens and closes. Our use case seems to be too complex for it, however.
Vanilla JavaScript
In a moment of minimalism, we decided to scrap all frameworks and libraries. What do they give us anyway apart from dependency hell and layers and layers of abstraction?
After implementing the navigation in JavaScript, it became clear that we did not want to further go down this route.
function loadNavigation() {
const closeButton = document.getElementById("navigation-close-button");
const openButton = document.getElementById("navigation-open-button");
const navigationOpen = document.getElementById("navigation-open");
const navigationClosed = document.getElementById("navigation-closed");
closeButton.addEventListener("click", function (event) {
navigationOpen.classList.add("d-none");
navigationClosed.classList.remove("d-none");
});
openButton.addEventListener("click", function (event) {
navigationOpen.classList.remove("d-none");
navigationClosed.classList.add("d-none");
});
}
Using JavaScript improved the dependency situation compared to AlpineJS, because there was one dependency less. But the gain was minimal, AlpineJS is just very lightweight and easy to include.
All of a sudden we had references to DOM nodes including the maintenance burden they bring. No thanks!
HTMX
The next piece of technology we tried out was HTMX, which further reduced the amount of JavaScript we had to write.
Meanwhile, we started using the navigation component of Bootstrap 5, so there was no custom JavaScript to write.
Feeling empowered by the good documentation and useful examples on the HTMX website, we decided to implement infinite scrolling. Half an hour later, we had the first working version.
In a rush of euphoria, we decided to HTMXize the whole project; liking, unliking, selling, buying, and updating the balance.
It went quite well, we implemented all those features without duplicating code in the backend and on the client.
This is how the markup of the like feature looks like:
<button
id="piece-detail-like-toggle-button"
hx-post="{% url 'core:like' details.piece.id %}"
hx-swap="outerHtml"
hx-target="#piece-detail-dynamic"
type="button"
class="btn btn-outline-secondary"
>
<i class="bi bi-suit-heart"></i>
</button>
HTMX truly feels like an extension of HTML, something that should have been standardized and included in HTML a while ago.
There seems to be a movement towards server-side rendering + smartness like Liveview, Blazor, Livewire, and Hotwire.
To this date, HTMX is powering the dynamic and interactive elements of hoarddit.
There is a bit of custom JavaScript that allows the user to like a picture by double tap or rendering price charts.
Running Out of Innovation Points
This blog post was written with the power of hindsight and we make it sound like we spent innovation points very precisely in a controlled way. That was not the case.
In search of simplicity and boredom, we initially deployed hoarddit to AWS Elastic Beanstalk. This worked quite well until we needed workers.
The Beanstalk way to do this is to use a separate worker environment within the same Beanstalk project.
Back then, hoarddit used huey which we were not able to get working on Beanstalk. So we kept trying out queues until we found one that worked.
It felt weird to not have an identical setup locally, but the deployment to Beanstalk was quite ergonomic.
And then we needed a staging environment. On Beanstalk, this means a second project with the same environments, which means twice the costs.
The Beanstalk deployments were sometimes hanging for no obvious reason, so we decided to self-host. We did not need Elastic Load Balancer anyway.
We got ourselves a small VPS at Hetzner and deployed everything with Dokku. Dokku is a great piece of simple technology that deserves its own blog post.
Summary
Finishing up a pet project that was built over several months with a couple of hours every other weekend feels amazing.
Hoarddit has a few active users and the early feedback we got is positive. Many requested social features that make things others do more visible.
If you have any feedback or feature requests, don’t hesitate to email at hello@hoarddit.com.